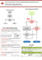
Application Areas:(2)
[Translation Services]
information retrieval(14)
Privacy preservation(2)
Natural Language Processing/Others:(14)
Data Mining(12)
Frequent pattern mining(6)
n-gram(6)
Text Mining(4)
Sequential Pattern Mining(3)
noise reduction(3)
Sentiment analysis(3)
Summarization(3)
Familiarity(2)
Authorship Identification(1)
Textual Entailment(1)
Human factors(5)
multi-cultural backgrounds(2)
voting(2)
WEB/Information Retrieval:(11)
search engine(5)
positional(4)
String Search(3)
Snippets(3)
website segment crawler(1)
robot(2)
focused crawler(1)
Personalized PageRank(1)
document navigation(1)
Cache Pruning(1)
Live Search(1)
Computer Architecture/Image Processing/SNS:(15)
[Computer Architecture]
[Processing]
[SNS]
Fully homomorphic encryption(7)
Ciphertext packing(4)
Bootstrapping(3)
Ciphertext Caching(1)
Parallel Distributed Processing(1)
Data Clustering(1)
Data Parallel(1)
Data Stream(1)
Content-aware image resizing(2)
Low resolution(1)
Twitter(12)
Author Profiling(2)
Cloud computing(2)
Facebook(1)
ligand-binding site(1)
UI/Data Analysis/Algorithm:(9)
[UI/Input Devices]
[Data Analysis/Algorithm]
Handwritten documents(7)
Annotation(6)
Digital Ink(6)
Gaze(2)
Eye tracking(1)
Active Reading(1)
Burrows-Wheeler Transform(3)
position specific scoring matrix(1)
classifier ensemble(1)
Algorithm/Evaluation/Bioinformatics:(12)
[Algorithm/Evaluation]
[Bioinformatics]
machine learning(15)
NTCIR(3)
Item Intervals(2)
Mobility(2)
trustworthiness(1)
Copy Detection(1)
Interaction styles(1)
Producer-Consumer(1)
Genome Sequence(3)
PBWT(3)
Kidera factors(1)
MoRFs(1)
YAMANA,co-author:(50)
Hayato YAMANA(42)
Hiroki Asai(10)
Yu Ishimaki(7)
Hiroki Imabayashi(5)
Akira Umayabara(4)
Yu Hirate(4)
Takanori UEDA(3)
Kana Shimizu(3)
Masahiro Tanaka(3)
Jiawen LE(3)
Lan WANG(2)
Jungkyu Han(2)
Kazuya Uesato(2)
Koji Nuida(2)
Tamotsu Noguchi(2)
Chun Fang(2)
Guanying Zhou(2)
Daiki Ito(1)
Syunya Okuno(1)
Koh SATOH(1)
Sayaka AKIOKA(1)
Takuya Funahashi(1)
Kosuke MORIMOTO(1)
Takuya Funahashi(1)
Naoyoshi Aikawa(1)
Yoichi MURAOKA(1)
Takashi Tashiro(1)
Shino Fujiki(1)
Taisuke Hori(1)
Daichi SUZUKI(1)
Akira Umezawa(1)
Arnon RUNGSAWANG(1)
Duy-Dinh Le(1)
han-Bin Chan(1)
Hideki NISHIMURA(1)
Hiroyuki KAWANO(1)
Hiroyuki KUSUMOTO(1)
Isao ASAI(1)
Kent TAMURA(1)
Masanori HARADA(1)
Naoyuki Saida(1)
Satoshi KAMEI(1)
Shin Kato(1)
Takashi FUKUDA(2)
Xuan ZHANG(2)
Shin’ichi Satoh(1)
Tanaphol SUEBCHUA(1)
Tetsuya Sakai(1)
Yixuan He(1)
Yoichi SHINODA(1)
:()
Saga search results:
Saga search results:
 ❏Community QA Question Classification:Is the Asker Looking for Subjective Answers or Not?
❏Community QA Question Classification:Is the Asker Looking for Subjective Answers or Not?
 ❏Experiments of Collecting WWW Information using Distributed WWW Robots
❏Experiments of Collecting WWW Information using Distributed WWW Robots
 ❏国会議事録を用いた経済指標のナウキャスティング
❏国会議事録を用いた経済指標のナウキャスティング
 ❏多言語表示に対する視線情報を用いた第一・第二言語推定
❏多言語表示に対する視線情報を用いた第一・第二言語推定
 ❏結合・非結合時における特異な特徴量を用いたGタンパク共役受容体と化学化合物の結合予測
❏結合・非結合時における特異な特徴量を用いたGタンパク共役受容体と化学化合物の結合予測
 ❏字配りの平均化による手書き文章の魅力的な文字配置方法
❏字配りの平均化による手書き文章の魅力的な文字配置方法
 ❏What is your Mother Tongue?: Improving Chinese Native Language Identification by Cleaning Noisy Data and Adopting BM25
❏What is your Mother Tongue?: Improving Chinese Native Language Identification by Cleaning Noisy Data and Adopting BM25
 ❏電子ドキュメント上での書き込みを支援する手書きアノテーション認識モデル
❏電子ドキュメント上での書き込みを支援する手書きアノテーション認識モデル
 ❏メンション情報を利用したTwitterユーザプロフィール推定
❏メンション情報を利用したTwitterユーザプロフィール推定
 ❏Cross-lingual Investigation of User Evaluations for Global Restaurants
❏Cross-lingual Investigation of User Evaluations for Global Restaurants
 ❏意味概念に基づいた関連論文検索システムー近傍文書からのキーフレーズ出を用いた自動クエリ生成ー
❏意味概念に基づいた関連論文検索システムー近傍文書からのキーフレーズ出を用いた自動クエリ生成ー
 ❏領域分割結果の投票処理を用いた背景に頑健な衣服領域抽出
❏領域分割結果の投票処理を用いた背景に頑健な衣服領域抽出
 ❏結晶化環境におけるpH値を考慮したSVMによるタンパク質結晶化の予測
❏結晶化環境におけるpH値を考慮したSVMによるタンパク質結晶化の予測
 ❏2-wayprediction法によるGPCRリガンドの結合予測
❏2-wayprediction法によるGPCRリガンドの結合予測
 ❏Sequential Pattern Mining with Time Intervals
❏Sequential Pattern Mining with Time Intervals
 ❏表情・動作情報とタッチパネル操作情報の統合による 学習状態の推定
❏表情・動作情報とタッチパネル操作情報の統合による 学習状態の推定
 ❏強調表記を利用した手書きドキュメント検索スニペット生成
❏強調表記を利用した手書きドキュメント検索スニペット生成
 ❏携帯端末に適用可能なモーションブラー警告システム
❏携帯端末に適用可能なモーションブラー警告システム
 ❏品詞 n-gram を用いた著者推定手法ー話題に体する頑健性の評価
❏品詞 n-gram を用いた著者推定手法ー話題に体する頑健性の評価
 ❏Generalized Sequential Pattern Mining with Item Intervals
❏Generalized Sequential Pattern Mining with Item Intervals
 ❏EPCI: Extracting Potentially Copyright Infringement Texts from the Web
❏EPCI: Extracting Potentially Copyright Infringement Texts from the Web
 ❏検索エンジンのヒット数の信頼性に対する評価
❏検索エンジンのヒット数の信頼性に対する評価
 ❏商用検索エンジンの検索結果では取得できないランキング下位部分の収集・解析
❏商用検索エンジンの検索結果では取得できないランキング下位部分の収集・解析
 ❏TF2P-growth: An Efficient Algorithm for Mining Frequent Patterns without any Thresholds
❏TF2P-growth: An Efficient Algorithm for Mining Frequent Patterns without any Thresholds
 ❏Poster: Privacy-Preserving String Search for Genome Sequences using Fully Homomorphic Encryption
❏Poster: Privacy-Preserving String Search for Genome Sequences using Fully Homomorphic Encryption
 ❏Why people go to unfamiliar areas? : Analysis of mobility pattern based on users’ familiarity
❏Why people go to unfamiliar areas? : Analysis of mobility pattern based on users’ familiarity
 ❏検索エンジンを使った翻訳サポートシステムの構築
❏検索エンジンを使った翻訳サポートシステムの構築
 ❏強化学習並列化による学習の高速化
❏強化学習並列化による学習の高速化
 ❏サーチエンジンGoogle
❏サーチエンジンGoogle
 ❏Bag-of-featureを用いた三次元類似形状検索
❏Bag-of-featureを用いた三次元類似形状検索
 ❏Detecting Learner’s To-Be-Forgotten Items using Online Handwritten Data
❏Detecting Learner’s To-Be-Forgotten Items using Online Handwritten Data
 ❏Reliability Verification of Search Engines’ Hit Counts
❏Reliability Verification of Search Engines’ Hit Counts
 ❏QueueLinker : Distributed Producer/Consumer Queue Framework
❏QueueLinker : Distributed Producer/Consumer Queue Framework
 ❏形態素間の優先関係を考慮した略語生成手法
❏形態素間の優先関係を考慮した略語生成手法
 ❏配列プロファイルを利用したドメインリンカー予測
❏配列プロファイルを利用したドメインリンカー予測
 ❏医薬品の既知の副作用に着目した未知の副作用推定手法の提案
❏医薬品の既知の副作用に着目した未知の副作用推定手法の提案
 ❏字幕テキストの利用によるブログで引用されたテレビ番組名の推定
❏字幕テキストの利用によるブログで引用されたテレビ番組名の推定
 ❏107億のWebページ解析とWebページ間最短経路探索システムの構築
❏107億のWebページ解析とWebページ間最短経路探索システムの構築
 ❏Identifying Molecular Recognition Features in Disordered Proteins
❏Identifying Molecular Recognition Features in Disordered Proteins
 ❏リンク構造を利用したWebページの更新判別手法
❏リンク構造を利用したWebページの更新判別手法
 ❏WSD Team’s Approaches for Textual Entailment Recognition at the NTCIR10 (RITE2)
❏WSD Team’s Approaches for Textual Entailment Recognition at the NTCIR10 (RITE2)
 ❏回答のクラスタリングによる多様な主観的回答を行う相談システムの提案
❏回答のクラスタリングによる多様な主観的回答を行う相談システムの提案
 ❏マイクロブログを対象とした100,000人レベルでの著者推定手法の提案
❏マイクロブログを対象とした100,000人レベルでの著者推定手法の提案
 ❏A Challenge of Authorship Identification for Ten-thousand-scale Microblog Users
❏A Challenge of Authorship Identification for Ten-thousand-scale Microblog Users
 ❏Adaptive Focused Website Segment Crawler
❏Adaptive Focused Website Segment Crawler
 ❏QueueLinker: A Framework for Parallel Distributed Processing of Data Streams
❏QueueLinker: A Framework for Parallel Distributed Processing of Data Streams
 ❏オンライン手書きデータを用いた学習者のつまずき検出
❏オンライン手書きデータを用いた学習者のつまずき検出
 ❏検索ヒット数の正確性評価−大規模クロールデータに対する文書頻度との比較−
❏検索ヒット数の正確性評価−大規模クロールデータに対する文書頻度との比較−
 ❏2段階GrabCutを用いた注目物体の視認性を向上させたサムネイル生成
❏2段階GrabCutを用いた注目物体の視認性を向上させたサムネイル生成
 ❏カスタマイズ性とリアルタイムなデータ提供を考慮したクローラの設計と実装
❏カスタマイズ性とリアルタイムなデータ提供を考慮したクローラの設計と実装
 ❏テレビ番組に対する意見をもつTwitterユーザのリアルタイム検出
❏テレビ番組に対する意見をもつTwitterユーザのリアルタイム検出
 ❏オンライン手書きデータによる記憶度推定システムの構築
❏オンライン手書きデータによる記憶度推定システムの構築
 ❏EA Snippets: Generating Summarized View of Handwritten Documents Based on Emphasis Annotations
❏EA Snippets: Generating Summarized View of Handwritten Documents Based on Emphasis Annotations
 ❏学習者の記憶の度合とオンライン手書きデータの関係性の調査
❏学習者の記憶の度合とオンライン手書きデータの関係性の調査
 ❏医薬品副作用情報を用いた副作用検索システムの提案
❏医薬品副作用情報を用いた副作用検索システムの提案
 ❏国会議事録を用いた経済指標のナウキャスティング
❏国会議事録を用いた経済指標のナウキャスティング
 ❏ウェブクローラ向けの効率的な重複URL検出手法
❏ウェブクローラ向けの効率的な重複URL検出手法
 ❏Hit Count Dance ー検索エンジンのヒット数に体する信頼性検証ー
❏Hit Count Dance ー検索エンジンのヒット数に体する信頼性検証ー
 ❏集約度を制約とした系列パターンマイニングによるコーディングパターン抽出の提案
❏集約度を制約とした系列パターンマイニングによるコーディングパターン抽出の提案
 ❏高速ストレージ環境におけるDBMSクエリのI/O並列化に関する検討
❏高速ストレージ環境におけるDBMSクエリのI/O並列化に関する検討
 ❏筆記者の強調表現に基づいたオンライン手書きノートの圧縮サムネイル生成手法
❏筆記者の強調表現に基づいたオンライン手書きノートの圧縮サムネイル生成手法
 ❏EA Snippets: Generating Summarized View of Handwritten Documents based on Emphasis Annotations
❏EA Snippets: Generating Summarized View of Handwritten Documents based on Emphasis Annotations
 ❏Fast and Space-Efficient Secure Frequent Pattern Mining by FHE
❏Fast and Space-Efficient Secure Frequent Pattern Mining by FHE
 ❏Condensing position-specific scoring matrixs by the Kidera factors for ligand-binding site prediction
❏Condensing position-specific scoring matrixs by the Kidera factors for ligand-binding site prediction
 ❏検索エンジンを用いた英文冠詞誤りの検出
❏検索エンジンを用いた英文冠詞誤りの検出
 ❏検索エンジン 2005 - webの道しるべ - 検索エンジンの概要
❏検索エンジン 2005 - webの道しるべ - 検索エンジンの概要
 ❏単独記事フィルタリングを用いた時系列ニュース記事分類法の提案
❏単独記事フィルタリングを用いた時系列ニュース記事分類法の提案
 ❏Detecting Student Frustration based on Handwriting Behavior
❏Detecting Student Frustration based on Handwriting Behavior
 ❏Intelligent Ink Annotation Framework that uses User’s Intention in Electronic Document Annotation
❏Intelligent Ink Annotation Framework that uses User’s Intention in Electronic Document Annotation
 ❏完全準同型暗号を用いた高速なゲノム秘匿検索
❏完全準同型暗号を用いた高速なゲノム秘匿検索
 ❏特定分野を対象とした単語重要度計算手法の提案とTwitter における専門性推定への適応
❏特定分野を対象とした単語重要度計算手法の提案とTwitter における専門性推定への適応
 ❏A Comparative Study of User Evaluations for Global Restaurants under the Multi-cultural Backgrounds
❏A Comparative Study of User Evaluations for Global Restaurants under the Multi-cultural Backgrounds
 ❏非テキスト情報のみを用いた AROWによる効率的な CTR予測モデルの構築
❏非テキスト情報のみを用いた AROWによる効率的な CTR予測モデルの構築
 ❏3軸加速度計を用いたデスクワーク中の割り込み可能性の推定
❏3軸加速度計を用いたデスクワーク中の割り込み可能性の推定
 ❏特定言語Webページ収集のためのフォーカストクローラの性能改善手法
❏特定言語Webページ収集のためのフォーカストクローラの性能改善手法
 ❏距離と属性を制約としたPrefixSpanによる感情表現抽出
❏距離と属性を制約としたPrefixSpanによる感情表現抽出
 ❏Robust Chinese Native Language Identification with Skip-gram
❏Robust Chinese Native Language Identification with Skip-gram
 ❏シーンテキスト位置の高速検出手法の提案
❏シーンテキスト位置の高速検出手法の提案
 ❏Twitterユーザを対象とした属性推定の精度向上
❏Twitterユーザを対象とした属性推定の精度向上
 ❏Image Annotation Fusing Content-based and Tag-based Technique Using Support Vector Machine and Vector Space Model
❏Image Annotation Fusing Content-based and Tag-based Technique Using Support Vector Machine and Vector Space Model
 ❏ウェブサーチエンジンに見る統合検索
❏ウェブサーチエンジンに見る統合検索
 ❏字幕テキストの利用によるマイクロブログからのテレビ番組に言及したメッセージ検出手法
❏字幕テキストの利用によるマイクロブログからのテレビ番組に言及したメッセージ検出手法
 ❏分散Key-Valueデータベースを用いたRDFストアの構築と評価
❏分散Key-Valueデータベースを用いたRDFストアの構築と評価
 ❏商品評価ツイートからの属性語自動抽出手法の提案
❏商品評価ツイートからの属性語自動抽出手法の提案
 ❏jQueryプラグインに特化したアニメーションサムネイル自動生成手法
❏jQueryプラグインに特化したアニメーションサムネイル自動生成手法
 ❏Multiple Kernel Learningを用いた階層的画像分類
❏Multiple Kernel Learningを用いた階層的画像分類
 ❏繰り返し表現を含んだ感情的なツイートの抽出
❏繰り返し表現を含んだ感情的なツイートの抽出
 ❏経時的な関連語句の変化を考慮したクエリ拡張によるTwitterからの情報抽出手法
❏経時的な関連語句の変化を考慮したクエリ拡張によるTwitterからの情報抽出手法
 ❏Secure Frequent Pattern Mining by Fully Homomorphe Encryptiop with Ciphertext Packing
❏Secure Frequent Pattern Mining by Fully Homomorphe Encryptiop with Ciphertext Packing
 ❏顔文字推薦のための感情辞書自動生成手法
❏顔文字推薦のための感情辞書自動生成手法
 ❏マイクロブログを対象とした著者推定手法の提案 −10,000人レベルでの著者推定−
❏マイクロブログを対象とした著者推定手法の提案 −10,000人レベルでの著者推定−
 ❏オンライン手書きノートからの強調語抽出
❏オンライン手書きノートからの強調語抽出
 ❏Identifying functional site of disordered proteins
❏Identifying functional site of disordered proteins
 ❏携帯端末に適用可能なモーションブラー警告システム
❏携帯端末に適用可能なモーションブラー警告システム
 ❏入力ストローク数削減による高速手書き入力手法
❏入力ストローク数削減による高速手書き入力手法
 ❏Twitterにおけるアカウント乗っ取りによるスパムツイートの検出
❏Twitterにおけるアカウント乗っ取りによるスパムツイートの検出
 ❏Retweet Reputation: A Bias-Free Evaluation Method for Tweeted Contents
❏Retweet Reputation: A Bias-Free Evaluation Method for Tweeted Contents
 ❏全世界のWebサーバの地理的位置・バックリンク数の解析
❏全世界のWebサーバの地理的位置・バックリンク数の解析
 ❏Privacy-Preserving String Searchfor Genome Sequences with FHE bootstrapping optimization
❏Privacy-Preserving String Searchfor Genome Sequences with FHE bootstrapping optimization
 ❏Secure Frequent Pattern Mining by Fully Homomorphic Encryption with Ciphertext Packing
❏Secure Frequent Pattern Mining by Fully Homomorphic Encryption with Ciphertext Packing
 ❏並列分散処理による2段階ランキングアルゴリズム
❏並列分散処理による2段階ランキングアルゴリズム
 ❏Producer-Consumer型モジュールで構成された並列分散 Webクローラの開発
❏Producer-Consumer型モジュールで構成された並列分散 Webクローラの開発
 ❏WSD Team’s Approaches for Textual Entailment Recognition at the NTCIR10 (RITE2)
❏WSD Team’s Approaches for Textual Entailment Recognition at the NTCIR10 (RITE2)
 ❏Legible Thumbnail: Summarizing On-line Handwritten Documents based on Emphasized Expressions
❏Legible Thumbnail: Summarizing On-line Handwritten Documents based on Emphasized Expressions
 ❏プロフィール情報とフォロー関係を組み合わせたTwitterユーザコミュニティの抽出手法
❏プロフィール情報とフォロー関係を組み合わせたTwitterユーザコミュニティの抽出手法
 ❏Web上の文章を対象とした著作権違反自動検知システム
❏Web上の文章を対象とした著作権違反自動検知システム
 ❏システムコールレベルのアクセスログを用いたディスクアクセスパターンマイニング
❏システムコールレベルのアクセスログを用いたディスクアクセスパターンマイニング
 ❏スマートウォッチにおけるアイズフリー日本語入力手法
❏スマートウォッチにおけるアイズフリー日本語入力手法
 ❏マイクロブログにおける単語間の依存性を考慮した語義曖昧性解消
❏マイクロブログにおける単語間の依存性を考慮した語義曖昧性解消
 ❏SVパッキングによる完全準同型暗号を用いた安全な委託Apriori高速化
❏SVパッキングによる完全準同型暗号を用いた安全な委託Apriori高速化
 ❏Twitterにおけるアカウント乗っ取りによるスパムツイートの検出
❏Twitterにおけるアカウント乗っ取りによるスパムツイートの検出
 ❏Model-Based Eye-Tracking Method for Low-Resolution Eye-Images
❏Model-Based Eye-Tracking Method for Low-Resolution Eye-Images
 ❏Cross-lingual Investigation of User Evaluations for Global Restaurants
❏Cross-lingual Investigation of User Evaluations for Global Restaurants
 ❏Twitter アクティブ認証精度向上のための文字N-gram IDFの提案
❏Twitter アクティブ認証精度向上のための文字N-gram IDFの提案
 ❏Personalized PageRankを利用した網羅的Twitterユーザ属性推定
❏Personalized PageRankを利用した網羅的Twitterユーザ属性推定
 ❏Comparison of Community Detection Methods for Facebook Ego Network
❏Comparison of Community Detection Methods for Facebook Ego Network
 ❏生成型一文要約のためのマルチアテンションモデルの提案
❏生成型一文要約のためのマルチアテンションモデルの提案
 ❏Predicting Various Types of User Attributes in Twitter by Using Personalized PageRank
❏Predicting Various Types of User Attributes in Twitter by Using Personalized PageRank
 ❏きたああああああああああああああああ!!!!!11: マイクロブログを用いた教師なし叫喚フレーズ抽出
❏きたああああああああああああああああ!!!!!11: マイクロブログを用いた教師なし叫喚フレーズ抽出
 ❏Why people go to unfamiliar areas? : Analysis of mobility pattern based on users’ familiarity
❏Why people go to unfamiliar areas? : Analysis of mobility pattern based on users’ familiarity
 ❏レビューサイトにおけるレビューおよびレビュアーの信頼性評価
❏レビューサイトにおけるレビューおよびレビュアーの信頼性評価
 ❏品詞と助詞の出現パターンを用いた類似著者の推定とコミュニティ抽出
❏品詞と助詞の出現パターンを用いた類似著者の推定とコミュニティ抽出
 ❏検索時間の調整を可能とした類似動画検索手法
❏検索時間の調整を可能とした類似動画検索手法
 ❏認知心理学的記憶調査に基づく記憶支援システムの構築
❏認知心理学的記憶調査に基づく記憶支援システムの構築
 ❏大規模候補者群に対する著者推定手法の提案と評価
❏大規模候補者群に対する著者推定手法の提案と評価
 ❏述語項構造と機能表現の比較と機械学習を併用した 文章の含意関係認識手法
❏述語項構造と機能表現の比較と機械学習を併用した 文章の含意関係認識手法
 ❏PlusDBG: Web Community Extraction Scheme Improving Both Precision and Pseudo-Recall
❏PlusDBG: Web Community Extraction Scheme Improving Both Precision and Pseudo-Recall
 ❏Topics and Influential User Identification in Twitter using Twitter Lists
❏Topics and Influential User Identification in Twitter using Twitter Lists
 ❏メンション情報を利用したTwitterユーザプロフィール推定における単語重要度算出手法の考察
❏メンション情報を利用したTwitterユーザプロフィール推定における単語重要度算出手法の考察
 ❏データストリーム処理におけるレイテンシ削減と高可用性のためのオペレータ実行方法
❏データストリーム処理におけるレイテンシ削減と高可用性のためのオペレータ実行方法
 ❏全世界のWebサイトのTLD・言語分布・地理的設置位置の特定
❏全世界のWebサイトのTLD・言語分布・地理的設置位置の特定
 ❏複数特徴量の統合による画像劣化検知システム
❏複数特徴量の統合による画像劣化検知システム
 ❏原語における形態素間の相対的な優先関係を利用した略語自動推定
❏原語における形態素間の相対的な優先関係を利用した略語自動推定
 ❏完全準同型暗号のデータマイニングへの利用に関する研究動向
❏完全準同型暗号のデータマイニングへの利用に関する研究動向
 ❏商用検索エンジンのヒット数に対する信頼性の検証
❏商用検索エンジンのヒット数に対する信頼性の検証
 ❏インターネットオークションにおける不正行為者の発見支援
❏インターネットオークションにおける不正行為者の発見支援
 ❏Fast and Space-Efficient Secure Frequent Pattern Mining by FHE
❏Fast and Space-Efficient Secure Frequent Pattern Mining by FHE
 ❏Poster: Privacy-Preserving String Search for Genome Sequences using Fully Homomorphic Encryption
❏Poster: Privacy-Preserving String Search for Genome Sequences using Fully Homomorphic Encryption
 ❏電子ペンを利用した数学手書き答案の戦略分類手法 〜多項式展開問題を題材として〜
❏電子ペンを利用した数学手書き答案の戦略分類手法 〜多項式展開問題を題材として〜
 ❏N-gram と離散型共起表現を用いたワードサラダ型スパム検出手法の提案
❏N-gram と離散型共起表現を用いたワードサラダ型スパム検出手法の提案
 ❏Intelligent Ink Annotation Framewrok that uses User’ s Intention in Electronic Document Annotation
❏Intelligent Ink Annotation Framewrok that uses User’ s Intention in Electronic Document Annotation
 ❏Identifying functional site of disordered proteins
❏Identifying functional site of disordered proteins
 ❏三角形特徴を用いた部分形状検索
❏三角形特徴を用いた部分形状検索
 ❏Identifying Topics and Influential Users based on Information Propagation in Twitter
❏Identifying Topics and Influential Users based on Information Propagation in Twitter
 ❏Web Structure in 2005
❏Web Structure in 2005
 ❏スマートウォッチにおけるアイズフリー日本語入力手法
❏スマートウォッチにおけるアイズフリー日本語入力手法
 ❏Locality-Sensitive Hashing を用いた大規模な著者推定の高速化
❏Locality-Sensitive Hashing を用いた大規模な著者推定の高速化
 ❏発話間関係の構造化による会議録からの議論マップ自動生成システム
❏発話間関係の構造化による会議録からの議論マップ自動生成システム
 ❏Localized Multiple Kernel Learning を用いた画像分類
❏Localized Multiple Kernel Learning を用いた画像分類
 ❏メンション情報を利用した Twitterユーザプロフィール推定
❏メンション情報を利用した Twitterユーザプロフィール推定